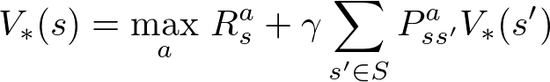������Դ�������ּ���
�����ݱ�����Q*���ܾ߱�GPT-4�����߱��Ļ�����ѧ����������ζ�����������������������������������Ʋ⣬����ܴ���OpenAI�������趨��AGIĿ��������һ��
��������OpenAI CEO�������ع飬������Ϸ��һ���䣬��������������δ�ӵ����⡣������Ϊ�ؼ��ģ����ǵ���������Ϊ�λᱻ���»��͡�
�������գ���ý��¶�����ڰ���������������ǰ�������о���Ա���»ᷢ����һ���ţ�����һ��ǿ���AI���֣�Q*��������вȫ���ࡣ���⣬OpenAI CTO Mira Murati��ǰ����Ա�����ڲ��ż����ᵽ��һ������Ϊ“Q*”����Ŀ�������ƣ�����ĿΪ“���»��������һϵ�в����е�����֮һ”��
�����ݶ��ý��²⣬Q*��OpenAIʵ��AGI�IJ���������٣�������������û�кͶ��»���ϸ��¶Q*�Ľ�չ�����ж����Ҳ���϶��»��ڽ�Ͱ�����ʱ��˵��“���붭�»ṵͨʱû��ʼ�ձ���̹��”��
�������ڱ����֮ǰ�����������ڹ�����б�ʾ��
����“��OpenAI����ʷ�ϣ������Ѿ�ȡ����4��ͻ�ƣ����һ�����ڹ�ȥ�ļ���������ǰ���֪����ɴ˺�£��ѷ��ֵ�ǰ����ǰ�ƽ�ʱ���Ҿ��ڷ����”
������ν�ĵ��Ĵ�ͻ�ƣ�ָ�Ŀ��ܾ���Q*��Ŀ��
����ʲô�� Q*��
����ʲô��Q*��
����Q*����Q star��ĿǰOpenAI�ڲ�û���κι���Q*����ϸ��Ϣ������
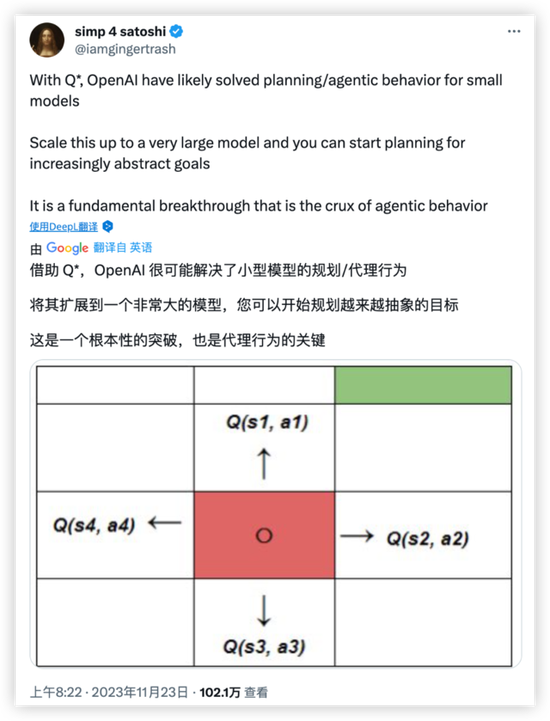
������һЩҵ����ʿ�²⣬���������ǻ���ѧϰ�㷨Q-Learning��Qѧϰ����ͬ��ʣ�Ҳ����OpenAI����Qѧϰ�㷨�������ģ�͵Ĵ��ţ�Ҳ����һ����ص���Ŀ���ơ�
�����Ƽ�����PC Guideָ����OpenAIʹ�õ�Q*ָ�Ĵ���DZ����������е�����ֵ������ Q*���ܴ���OpenAI�ҵ���ӽ���Ч���Ż��㷨�����Ž⡣
�����������֤ȯ ����ʦ���ص�˵����
����Qѧϰ��һ�ֻ���ǿ��ѧϰ���㷨�������������Ʒ���߹�����������ſ������⡣����Ŀ����ͨ��ѧϰ���Ų��ԣ�ʹ��������δ֪�������������ѡ��
����Qѧϰ���ݱ��������̸���״̬-������Ӧ��Qֵ���ƽ�����ֵ������������ͨ���뻷���������۲쵽�µ�״̬�ͽ�����������ִ�и���������Qֵ��
������ν���������̣�Ҳ����Ϊ��̬�滮���̣���ָ��ѧ�������·��������������ڽ�����Ӷ������Ĺ�ʽ��ͨ�����÷��̿����ҵ�����ֵ���������Ų��ԡ�
���������㷨���ˣ�����������������һ��Ŀ�꺯��������“����ʱ����̡��ɱ���͡��������Ч�����”�ȡ�Ȼ���㷨��������ȡ��������ж���ʵ��Ԥ�ڽ����
��������˵��Qѧϰ����ͨ��̽�����п��ܵ�·����ѧϰ��ͨ��Ԥ�ڽ��������·�������·�ߣ���ͨ���Դ��ҵ����Ż���·����������ʱ������ƴﵽ�Ż�״̬��ÿ�ζ��������õľ��ߡ�
������ý�屨�����ڰ����������֮ǰ��OpenAI���ڲ���Q*��������ʾ����ʾQ*�ܹ����Сѧ�̶ȵ���ѧ���⡣
������Ȼ���Сѧ��ѧ��������ûʲô��ɫ֮��������Ҫǿ�����ǣ�����GPT-4���ڣ����������Ƚ��Ĵ�����ģ��ͨ�������ó��������Ե�����ʹ��ԼӼ��˳������Ļ�����ѧ���᷸����
����������籨����˵��Q*������������ѧ���Ⲣ������ȷ�𰸣���ʹֻ��Сѧ��ѧ����Ҳ��ζ�ž�ķ�Ծ��������ѧ��������ζ������������������������������Ҳ��ζ��OpenAI�������趨��AGIĿ��������һ��
���������һЩ���Ѳ²⣬Q*�����ģ��ģ�Ϳ����Ѿ��߱�����ѧϰ�����ҸĽ��������������ܹ�ͨ����������Ϊ�ij��ں�����ڹ㷺�ij������������ӵľ��ߣ������Ѿ߱���������ʶ��
�������ֹۡ���������µļ�����ǣ�OpenAI�Ѿ�����˴���AGI�Ļ���������
���������������ף���ȷʵ�п�������ġ�
��2 [2] ��һҳ ��1ҳ ��2ҳ