�������߰�������AI����һ��ϣ���˽������ҵ�����·�չ���ƣ������ҵ��������CBInsights���������2019��AI���Ʊ�����������������������84ҳ�ı���ʶ����25��AI���ƣ�����CBInsights��NExTT������ܣ�����ҵ���öȺ��г���������ά�ȶ�����й��࣬����Ϊ��ͬ�����ɫ�ṩ���߲ο���
������ؼ������ǶԵ������������ʵ��������������ڰ���“����”�Σ���������㷺���û��кܳ�һ��·Ҫ�ߣ����ѧϰ�ǵ�ǰ����AIӦ�õ����档������Ϊ�������磬���ּ���������Ҫ�Ľ�һ���ˣ��Ƚ�ҽ�Ʊ���������ⶨ������о���Ա���ڿ�ʼ�����������о��Ͳⶨ��ǰ���������ķǵ��ͷ������أ��ܷ��ʴ��ͱ�ǩ����������ѵ��AI�㷨�ı��裬������ķ�������Ҳ���ܽ����һƿ����
����Ϊ�˷����λ�˽⣬36봶���25�����ƽ���ժҪ������ܡ�
��������
������Դ���
����AI�Ľ����ż���ÿ�ǰ�ĵͣ���Ҫ��л��Դ������
������2015��Google��ԴTensorFlow����ѧϰ��Ϊ���ˣ�����AI�����������ѧϰ���Ŀ�Դ����Ѿ��γɰٻ���ŵľ��棬������Facebook��PyTorch��������ѧϰ�㷨�о�����MILA����Theano��Keras��Microsoft Cognitive Toolkit�Լ�Apache MXNet�ȵȡ�
������ԴAI�����˫Ӯ�ľ��棺һ���������˶�������AI��������������������ҲΪ����Google�ȹ�˾��AI�о��ṩ�˰�����
����֪��AIר��Yoshua Bengio��ʾ��
����֧�����ѧϰ�о���������̬��ϵ��չ�úܿ죬�����Ѿ��ﵽ��һ�ֽ�����״̬����Դ������Ϊ�淶�����ֿ�ܳ��֣������˴�̽����ӱ�뷨����������ĸ��������Ҳ�ͬ��������ջҲ�ڴ̼��ľ�����Χ�µõ�����������ҵ��ҵ�֧�֡�
������ԵAI
������ʵʱ���ߵ��������ڽ�AI������Ե�ĵط���
�����������ֻ������������ɴ����豸�ȱ�Ե�豸������AI�㷨�������Ǹ�������ƽ̨�������ͨ�ţ�ʹ�ñ�Ե�豸�߱����ڱ��ش�����Ϣ�����������ҿ��Ը����ٵض����������Ӧ��
����Nvidia����ͨ��ƻ�������ɳ�����ҵ���ڿ������ڱ�Ե��AIר��оƬ��
������ԵAI�������ߵ��ӡ����š�ҽ��Ӱ���������ҵ����Ӧ�����塣�ȷ�˵�������ͷ������ʶ�𡢻�Ϊ��ƻ���������ֻ������������ʶ��Tesla AIоƬ�ļ�ʱ��ʻ���ߡ�Ӥ�������������˻����������Ӿ����������������ӣ��ȡ�
������2018�����˾�IJƱ����ϣ��ᵽ��Ե����Ĵ����Ѿ��������ࡣ
�����������ܱ�ԵAI���м�����ʱ�����ƣ���Ҳ���ھ��ޡ��Ǿ��Ǵ洢�ʹ��������ܵ����ơ�Ԥ�ƻ��и�����ģʽ���֣�ʹ�����ܱ�Ե�豸�ܹ����ͨ�Լ������ķ�����ͨ�š�
��������ʶ��
�������ֻ��������ǻ�����������ʶ�����ڽ���������
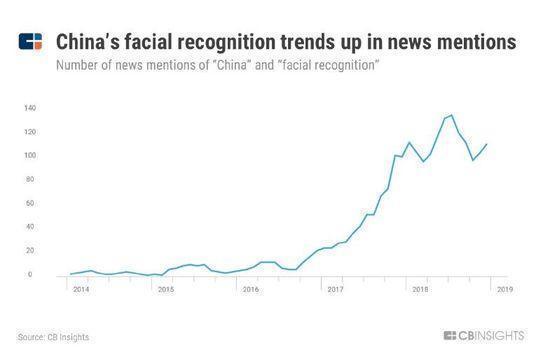
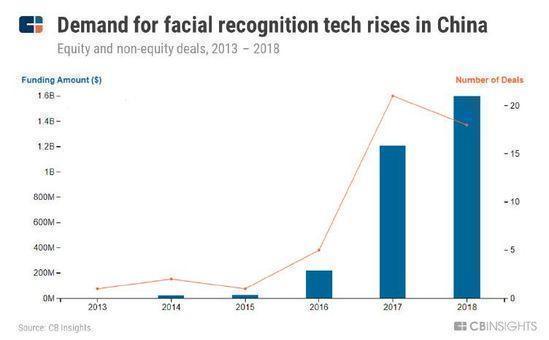
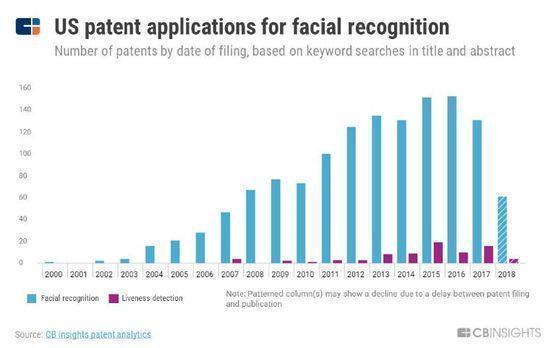
��������ʶ�����й���ý���ȶȴ�2016�꿪ʼ�Ͳ������¡�
�����й�������ʶ����������Ҳ��֮ͬ�������ⷽ���й��Ѿ�ð���������Ƽ���Face++��CloudWalk�ȶ����ޡ�
���������ⷽ��ĵ�ר������Ҳ�������Ƶ����ơ�
��������ʶ���������ҵӦ�����ڰ��������ۼ������ߵ���������֣�����Ѹ�ٳ�Ϊ��������ʶ���������ʽ��
������������ʶ��Ӧ������㷺�������ּ���������û��覴á����б�����Amazon��һλ������Ա�ϳ��˷�����ӡ��������ձ�������һ��У����Ƭ��Ϊ��߾�����ƭ��������ͼһ��ѧУ����������ͷ��
����ҽ��Ӱ�������
��������FDA���ڸ�AI��ҽ���豸���̵ơ�2018��4�£�FDA��������ר�Ҳ����������ɸ����������Ĥ���䲡�˵�AI����������������IDx-DR����ʶ���ʴﵽ��87.4%����û�д˲���ʶ����Ҳ�ﵽ��89.5%��
�������⣬FDA���˳�����ҵVia.ai��CTɨ����DZ���з�֢״֪ͨ����Viz LVO���Լ�������ҵArterys��Oncology AI�����������߿���ʶ��β���������ˡ�
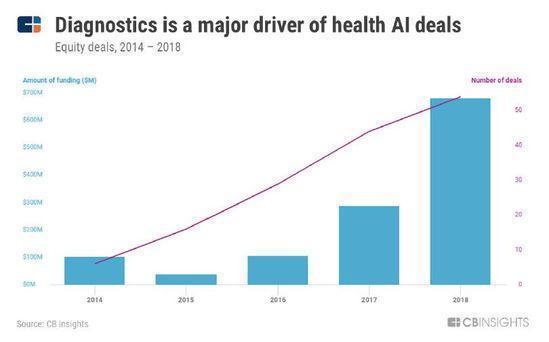
������ܵķ��ɸ���ҵ���������µĵ�·����2014������������80��AIӰ������Ϲ�˾�����149�����ʽ��ס�
����������ҵHealthy.io�ĵ�һ���ƷDip.io�������˴�ͳ����Һ������ֽ�����������·��Ⱦ���û��������ֻ�������ֽ��Ƭ��������Ӿ��㷨���ܸ��ݲ�ͬ�Ĺ�����������Ʒ�ʶԽ������У������Ʒ�ɼ���Ⱦ��������صIJ���֢������ŷ�ޡ���ɫ�����õ�Dip.ioҲ�ѻ��FDA���С�
����Ԥ����ά��
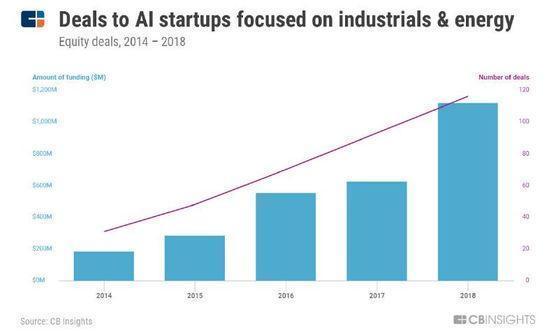
����AI��ҵ��������Ϊ�������̵��豸�����̵ļ����߽�ʡ��������Ԫ�����������ʧ��
����Ԥ����ά�����ô���������������ͷ���ϲɼ��������ݣ����¶ȡ�ѹ���ȣ������ɵ�ʵʱ���ݵĹ�ģ�Լ���ʽ�Ķ���ʹ�û���ѧϰ��Ϊ��ҵ���������ɻ�ȱ�����������ʱ�գ��㷨���ܹ���ǰԤ����ϡ�
������ҵ�������ɱ����½�������ѧϰ�㷨�Ľ�չ���Լ���Ե������ƽ�����Щ��ʹ��Ԥ����ά����Ӧ�ñ�ø��ӹ㷺��
��������ͼ���Կ������������Ͷ���������������
�������л�Ծ��Ͷ���߰���GE Ventures�������ӡ�SAP�ȡ��������ȴ�˾Ҳ���Լ��������Ե�����������������չ���ṩԤ����ά��������
����������������
�����������ʵ������������Ѿ��߳�“����”�Σ����Ǵ��ģ�������кܳ�һ��·Ҫ�ߡ�
������2002��������Amazon�Ѿ�������35����“�������”�йص�����ר�������а������þ���������“ȷ��һ��ͼ�����ѯͼ�����Ƶ���Ʒ”�����û���ѧϰ����ͼ����Ӿ������������ڴ˽���������ѯ�ȡ�
����eBay�����û���ѧϰ���������ҵIJ�Ʒ������Ȼ����Ѱ��ͬ���Ʒ��
�������Ǻܶ���Ҷ���ʹ����Ȼ���������в�ѯ����Ե�������������������ս�����˳�����ҵ���ǿ�ʼΪ�������ṩ����������
����ͼ������������ҵViSenze�Ŀͻ�����Uniqlo��Myntra������ȡ��������ý���ͻ�����ϲ���Ķ�������Ƭ��Ȼ���ϴ����������ҵ�ͬ���IJ�Ʒ��
������ð���Ͷ�ʵ���ɫ�г�����ҵTwiggle���ڻ��ڵ��������������濪������API������ҵ��ض�����������Ӧ��
��������
������������
�������ѧϰ�ǵ������AIӦ�õ����档�����ڽ������磬���ּ������ڿ�����Ҫ�Ľ�һ���ˡ�
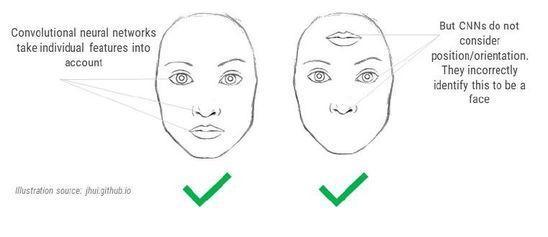
�����������磨CapsNet�������ѧϰ����Geoffrey Hinton 2017-18��ʱ����ĸ��ּ�ڿ˷���ǰͼ��ʶ������Ҫ�Ǿ���������CNN����ȱ�ݡ�
��������ȱ����Ҫ��2����һ������ʶ��ȷ�ռ��ϵ���ȷ�˵��ͼ�о�����͵����λ�÷����˸ı䣬CNN�ԻὫ��ʶ���������
�������������µ��ӽ�ȥ������ȷ�˵��ͼ�н���������ʶ��1��2��Ϊͬһ��ߵIJ�ͬ�ӽ��б���Ҫ��CNN��ɫ�öࡣCNN����Ҫ�����ѵ�����ݼ������ϳ�ÿ������Ķ����Ѿ��кڿ�ͨ��������������������CNN��Ŀ�����ϳ���������
��������Ŀǰ�Խ���������о��Դ��ڳ��ڽΣ����п��ܶ�Ŀǰ���Ƚ���ͼ��ʶ��������ս��
������һ������
�����dz����ڵ��о����ڳ��֣�ͨ���������������ѧϰ�Ľ����������������ѵ�����֮һ�������ԡ�
������2006�꿪ʼ��DARPA��Ͷ������������Ԫ��Լ�����ս�˹��ѧ�����Ƚ������ƻ����������˵��ϱ���������������������������ס�
�����ȷ�˵�ý�֫���֫����ָ�����Է��˶�����Ĵ��Ժͼ����źŽ��н�����Ȼ����ת��Ϊ�Զ����ƾ���Ҫ��ѧ�Ƶ�֪ʶ��
����������о���Ա�Ѿ���ʼ���û���ѧϰ��ֲ������Ĵ��������źŽ��н��룬Ȼ��֮����Ϊ�ƶ���֫�豸��ָ�
����Լ�����ս�˹��ѧ��Ӧ������ʵ����һ�������е���Ŀ��������“�����㷨ͨ��”�ӿ������Ƽ�֫�ġ�
����ȥ��6�£��¹����۹�����ѧԺ���о���Ա���û���ѧϰ�����֫�߲�֫���źţ����ü���������ƻ�е�ۡ�
������һ��˼·�������н����������������ü����ź�����������ͷ��Ȼ�����ü�����Ӿ��㷨����ץ�������Լ���ǰ����Ĵ�С��
�����ٴ�����Ǽ�
�����ٴ���������ƿ�����ڵǼǺ��ʵIJ��˿⡣ƻ���п��ܿ��Խ��������⡣
������������——Ҳ���ǿ����������ϵͳ������Ϣ������——��ҽ�Ʊ������������֮һ���������˲������ֻ���Ŭ����
�����ٴ��������ⷽ�������������أ������ʵ��������ʵ��IJ��˽���ƥ���Ǻܺ�ʱ�ҳ�����ս�Ĺ��̡���������Ŀǰ����18000���ٴ��о�������ļ���ˡ�
���������AI������������˹�����������ȡ���˲����������Ϣ����֮������е�������жԱȣ�Ȼ�����ƥ����о����顣
�����ڲ�����ҽ�Ʊ����ƻ�ƥ�䷽�棬ƻ���ȼ�����ͷ�Ѿ�ȡ����һ���ijɹ���
������2015�꿪ʼ��ƻ�����Ƴ���2����Դ���——ResearchKit��CareKit——�������ٴ�������ļ���ˣ�����Զ�̼�ز��˵Ľ���״������Щ���ʹ���о���Ա�Ϳ����ߵ��Դ���ҽ��app��������ǵ��ճ���������˵Ǽǵĵ����ϰ���ƻ�����ڸ����ŵĵ��Ӳ�����Ӧ�̺�����������������⡣
����2018��6�£�ƻ���������Ƴ���Health Records API���û����ڿ���ѡ���������Ӧ�ú�ҽ���о���Ա�������ݣ�Ϊ�������������ʽ��ش��µĻ��ᡣ
�������ɶԿ����磨GAN��
������������ȴ��������������ڱ�÷dz��ó������������ͼ��
���������ϳ�������Щͼ���Ǽٵ���
��������ȫ���ǡ���Щȫ����GAN��������ġ�
�������ɶԿ������ǷǼලʽѧϰ��һ�ַ�����ͨ������������������ĵķ�ʽ����ѧϰ���÷�����Google�о���ԱIan Goodfellow��2014����������ɶԿ�������һ������������һ���б�������ɡ����������DZ�ڿռ䣨latent space�������������Ϊ���룬����������Ҫ����ģ��ѵ�����е���ʵ�������б������������Ϊ��ʵ����������������������Ŀ���ǽ�����������������ʵ�����о����ֱܷ������������������Ҫ�����ܵ���ƭ�б����硣����������Կ������ϵ�������������Ŀ����ʹ�б��������ж�����������������Ƿ���ʵ��
��������GANʽ�Ĵ��ģ��Ŀ����Ҫ��ս�Ǽ���������Google�о���Ա�ڴ���“BigGAN”����512��TPU������512���ص�ͼ��һ������ĵ�Ĵ�ž�Ҫ2450��4915ǧ��ʱ֮�䡣���Ѿ��൱����ͨ������ͥ����ĵ�ġ�
��������GANҪ�����䣬AIӲ��Ҳ�IJ������䡣
����������Ȥ���������⣬GANҲ�������������;�������ð������Ƶ��ɫ����Ʒ�Ļ����ȡ�����GAN�о����������ּ����Ʊػ�����š�ý�塢���������簲ȫ������ս��GAN�Ѿ��ı�������ѵ��AI�㷨�ķ�ʽ��
��������ѧϰ
���������·���ּ���������û�����ѵ��AI��ͬʱ������˽��
�������Ǹ������豸���ճ��������Բ����ḻ�����ݣ���Щ��������ѵ��AI�㷨�Ļ����Լ���ظ�������֣�������Ը��Ӿ�ȷ��Ԥ���������Ҫ���������ʲô��������Щ�û�����Ҳ���漰��������˽���⡣
����Google�������������ѧϰ�ķ�����ּ��������һ�ḻ���ݼ���ͬʱ�����������ݡ������֮�����������Ȼ��������ֻ�����ᷢ�ͻ�洢���Ʒ������ϡ��������Ʒ����������°���㷨���㷨��“ȫ��״̬”���������ѡ����û��豸�ϡ�
��������ֻ������Ľ�Ȼ����ڱ��ػ������ݶ�ģ�ͽ��и��¡�֮��ֻ�����ָ��£��Լ����������û��ĸ��£���ش����Ʒ������Ը��Ƹ�“ȫ��״̬”��Ȼ���ٲ����ظ���һ���̡�
�����ѵ������¾ۺ�������������ʵ�������ʣ������㷨����������ˡ�����ѧϰ�IJ�ͬ���������������ݼ���������Ҫ������
����Non-IID�������ֲ�ʽ�㷨�����������Ƕ���ͬ�ֲ���Independent and identically distributed��IID���ģ�����ʵÿһ���ֻ����ɵ����ݶ��Ƕ��صģ���Ϊ��ͬ����ʹ��ϰ�߲�ͬ������ѧϰ���ǵ������ֲ�ͬ��
������ƽ�⣺ijЩ�û�ʹ��app���ӻ�Ծ����ȻҲ�������������ݡ����ÿһ���ֻ���ѵ��������Ҳ��һ����
����Firefox�Գ�������Ҫ������Ŀ����ʵ������ѧϰ������֮һ�����û������������URLʱ��Firefox����������ѧϰ����URL�Ƽ�������
����AI������ҵOWKIN����������ѧϰ���������еIJ������ݡ��䷽�������ò�ͬ�İ�֢���������ڲ������ݲ��뿪���ص�����½���Э����
�����Ƚ�ҽ�Ʊ�������ⶨ
�����о���Ա���ڿ�ʼ�������������о��Ͳⶨ��ǰ���������ķǵ��ͷ������ء�
����Google���о���Ա��������Ĥͼ��ѵ�������磬Ȼ�����ø�������ȥѰ����Ѫ�ܷ������ء����о����֣�ͨ������Ĥ��������ʶ�����䡢�Ա𡢳���ϰ�ߵȷ������أ������Զ���Щ����������һ���ľ�ȷ�̶ȡ�
�������Ƶأ�÷������Ҳ����ɫ�г�����ҵBeyond Verbal������ͨ��������������ѧ������Ѱ�ҹ��IJ��˶��ص��������ԡ��о����֣�������������һ����о���ʱ���������������Ը����IJ�����ǿ������
����������ҵCardiogram������о����֣��������ѧϰ��������������ʱ����Ըı��ͨ���ֳɵĿɴ������ʴ����������������⾫ȷ�ʿɴ�85%��
����AIѰ��ģʽ�������������Ϊ�µ���Ϸ�����ʶ���ǰδ֪�ķ������ؿ����µĵ�·��
�����Զ������
�������չ�˾�ͳ�����ҵ����ʼ��AI���㳵����“��������”�����¹ʳ���ͼƬ���з����������˾����Ϊ��
�������Ͻ����“�¹ʴ���ϵͳ”�����������ѧϰ�㷨������ͼƬ��������ȥ��Ҫ����Ա�ֳ��������������ڿ������Ƚ�ͼ�����е��ˡ�����ֻ���ϴ�������Ƭ�����Ͻ����������ͻ����ͼƬ���Զ�������ʧ������
�������Ͻ����������˾���ķ��յ�����Ӱ�쳵�յĶ���ģ�͡�������������ν��“���շ�”���������ü�¼������ϰ�ߡ���ʻϰ�ߵ����û���ѧϰ���㳵���ķ������֡�
����������ҵNexar����˾�����Լ��������ֻ������г���¼��ʹ�ã����ҽ���¼�ϴ���Nexar app�������ĺô��ǿ����г��յ��ۿۡ�
�����õ���Ƶ��app�����ü�����Ӿ��㷨���·����˾����Ϊ�Լ��¹ʡ�App���ṩ��“�¹�����”���ܣ����뱣�տͻ������������⡣
����������ҵTractable�����ñ��չ�˾��������ͼƬ����������ϴ������������ƽ̨��“AI Review”���ܾͿ��Խ���Щ��������еļ�ǧͼƬ�Աȣ�Ȼ�������Ӧ�Ķ��۵�����
��2 [2] ��һҳ ��1ҳ ��2ҳ
��������: �˹�����